
Recent times have seen remarkable evolution in language models, with (LLMs) Large Language Model Architectures leading the way. These models have transformed natural language processing (NLP), enabling accurate human-like text generation. This guide explores LLMs, delving into their history, development, and architecture. A key focus is on the Transformer model, a breakthrough in NLP, and its self-attention mechanisms enhancing language modeling.
History and Evolution of LLMs

The journey of LLMs began with statistical models but faced limitations in capturing language complexities. Neural networks like recurrent neural networks (RNNs) and Long short-term memory (LSTMs) brought advancements by addressing the challenges of sequential data processing.
RNNs attempted to capture context by propagating information through time, but their vanishing gradient problem hindered their ability to capture long-range dependencies. LSTMs, with their specialized memory cells and gating mechanisms, improved upon RNNs and became a breakthrough in modeling sequential data.
However, it was the transformer model that revolutionized NLP. Transformers’ self-attention mechanism enabled simultaneous consideration of different parts of an input sequence, thus capturing long-range dependencies effectively. This innovation not only surpassed the limitations of RNNs and LSTMs but also laid the foundation for remarkable advancements in language processing.
Find the Memory Limitations in Artificial Intelligence Error
Types of LLMs
There are several types of LLMs, each with its own unique characteristics and applications. Some of the most popular ones include
- OpenAI’s GPT (Generative Pre-trained Transformer)
- Google’s BERT (Bidirectional Encoder Representations from Transformers)
- Facebook’s RoBERTa (Robustly Optimized BERT Pretraining Approach).
- Anthropic’s Claude
- Cohere
These models are pre-trained on large amounts of text data and can be fine-tuned for specific tasks.
Architecture
As we delve deeper into the architecture of LLMs, we uncover a complex web of interconnected components that work harmoniously to empower these models with the ability to comprehend and generate human language. At the heart of LLMs lies the revolutionary Transformer model, a groundbreaking architecture that has redefined the landscape of NLP.
The Transformer Model: A Paradigm Shift
The Transformer model, first introduced by Vaswani et al. in 2017, (Vanilla Transformer) represents a departure from traditional sequential processing methods used in language models like RNNs and LSTM networks. Instead, the Transformer model adopts a parallelized approach, dramatically increasing efficiency and allowing for more effective modeling of long-range dependencies in language.
Self-Attention: Unveiling Complex Linguistic Relationships
A key feature of the Transformer architecture is self-attention, a mechanism that enables each word in a sequence to attend to all other words simultaneously. This powerful attention mechanism allows the model to weigh the importance of different words in the context of the entire input text, facilitating the capture of complex linguistic relationships.
Self-attention is a game-changer, as it empowers LLMs to understand the context and dependencies between words, even when they are distant from each other in the sentence.
Position Encoding: Enabling Sequential Understanding
To complement self-attention, the Transformer model utilizes position encoding. Since the Transformer processes words in parallel, there is no inherent sequential information about the word order. Position encoding provides the model with essential information about the relative positions of words in the input sequence, helping the model understand the sequential structure of the language.
Encoder-Decoder Structure: Handling Diverse Tasks
The Transformer architecture consists of an encoder-decoder structure. In tasks like language translation, the encoder processes the input text and transforms it into a set of contextualized embeddings. The decoder then takes these embeddings and generates the corresponding output text.
The power of the Transformer lies in its ability to handle both single-directional tasks like language modeling and bidirectional tasks like language translation with equal effectiveness.
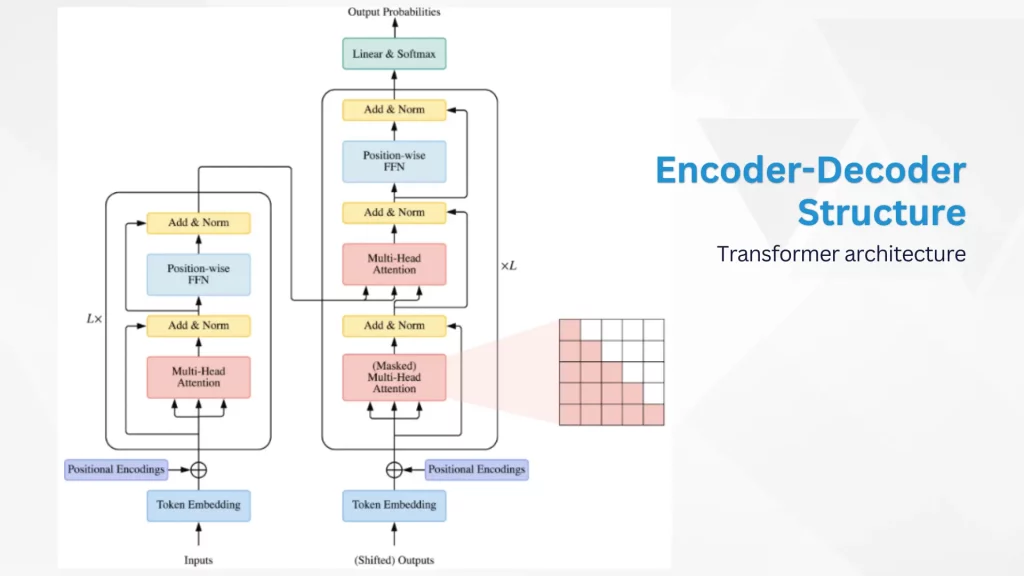
Source: https://www.sciencedirect.com/science/article/pii/S2666651022000146
Applications of LLMs
Due to its impressive capacity to capture intricate relationships and its effective concurrent computation, the Transformer design has emerged as the foundational structure for a range of Large Language Models (LLMs). Among these, a standout illustration is provided by OpenAI’s GPT series, encompassing GPT-2 and GPT-3. These models have attracted substantial recognition and praise due to their remarkable aptitude for generating language.
1. Wide-Ranging Applications
These LLMs have found applications across a wide range of domains. They excel in tasks such as language translation, where they can effortlessly convert text from one language to another, often outperforming traditional rule-based approaches. Additionally, LLMs have proven to be invaluable in text generation tasks, enabling the creation of coherent and contextually relevant content for various purposes.
2. Enhancing Sentiment Analysis
Sentiment analysis, a crucial aspect of understanding human emotions and opinions from text, has also been significantly enhanced by LLMs. Their ability to capture context and nuances in language allows them to discern sentiments more accurately and provide valuable insights for businesses and researchers alike.
3. Advanced Question Answering and Chatbots
Question-answering systems powered by LLMs have reached new heights, offering accurate and informative responses to user queries by leveraging vast amounts of pre-trained knowledge. Chatbots, too, have been revolutionized by LLMs, with their engaging and interactive conversations that simulate human-like interactions.
4. Diverse Applications: Content Recommendation and Summarization
Beyond traditional language processing tasks, LLMs have found application in content recommendation systems, offering users personalized suggestions based on their preferences and interests. Additionally, LLMs have demonstrated their prowess in summarization tasks, condensing lengthy texts into concise and informative summaries.
5. LLMs in Programming
The impressive capabilities of LLMs extend even to programming, where they have been utilized for code generation. These models can generate code snippets based on natural language descriptions, simplifying the process of software development for programmers.
Conclusion
LLMs have revolutionized natural language processing by capturing complex dependencies and long-range context in language. With its self-attention mechanism and position encoding, the Transformer model has played a crucial role in the success of LLMs. With their wide range of applications, LLMs are set to continue shaping the future of natural language processing and AI.
