
Generative Artificial Intelligence (AI) has become one of the most influential areas of modern data science, powering everything from large language models and image generation systems to synthetic data and scientific simulation. STAT 8105: Generative Artificial Intelligence Principles and Practices is a graduate-level course designed to provide a rigorous, statistics-driven foundation for understanding how these models work, why they work, and how to apply them responsibly in practice.
This course bridges classical statistical theory with modern machine learning, giving students both the principled understanding and practical skills needed to work with state-of-the-art generative models.
What exactly is STAT 8105 trying to do for you?
STAT 8105 is built to give you a clean, stats-first pathway into generative AI, not just a buzzword tour and not a copy-paste deep learning crash course. The scope usually spans the “why” (what problems generative models solve), the “how” (probability, inference, sampling), and the “so what” (where these models show up in real research and real products).
If you’ve seen generic machine learning courses that hover around prediction accuracy and classification benchmarks, this one tends to feel different. It leans into data generation, uncertainty, likelihoods, and the kind of modeling decisions statisticians actually argue about in the hallway.
Do you know: 7 Key Advantages of Generative AI for Businesses
Why does generative AI matter to modern statistics and AI, really?
Generative AI isn’t only about producing pretty images or writing surprisingly decent emails. At its core, it’s about learning the data generating process, or at least a useful approximation of it, so you can simulate, impute, augment, forecast, compress, or reason under uncertainty.
In modern statistics, that opens doors: synthetic data for privacy, simulation when real data is scarce, better missing-data strategies, and models that can express uncertainty without hand-wavy shortcuts. In modern AI, it is the engine behind foundation models, multimodal systems, and agent-style workflows that need plausible outputs, not just labels.
What are the foundations you must get right before the “cool models”?
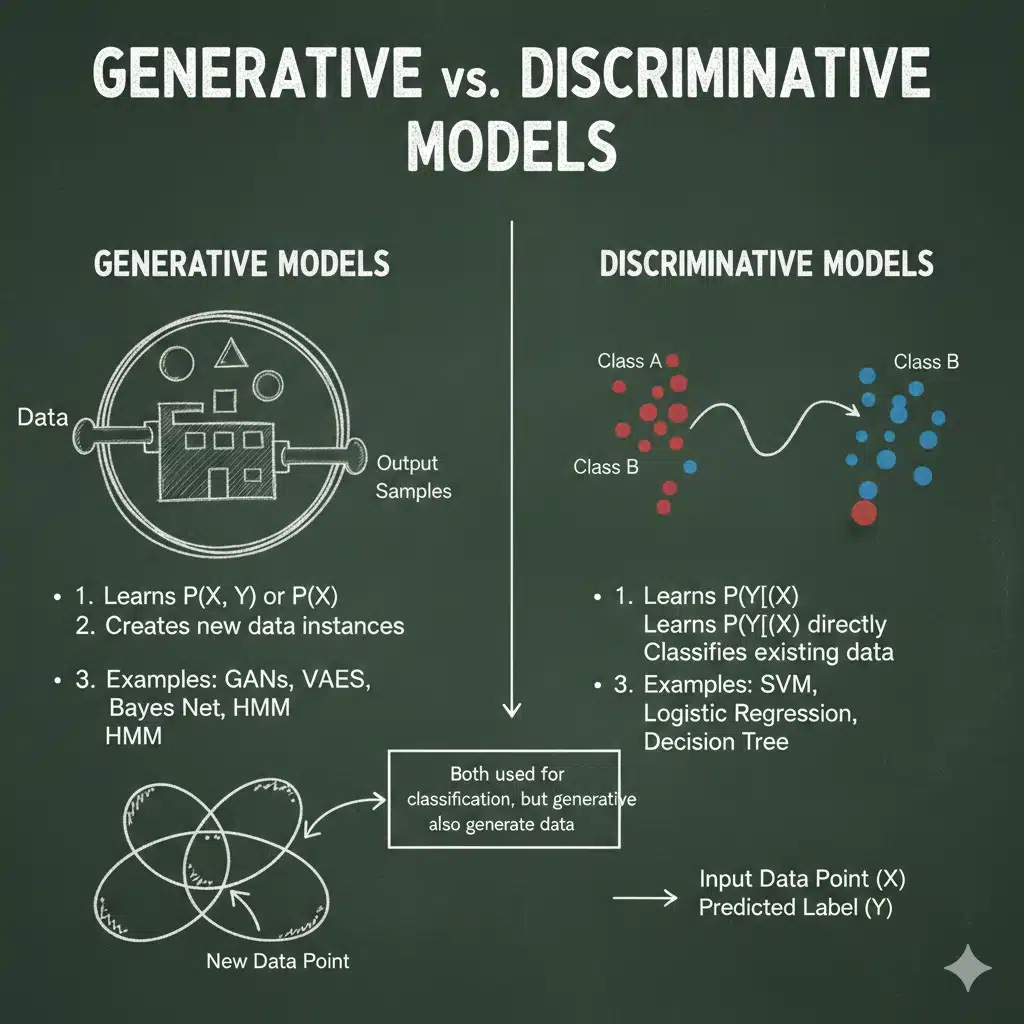
What is generative AI and how is it different from discriminative modeling?
Discriminative models learn , meaning they focus on predicting labels or outcomes given inputs. Generative models aim to learn
or
, which is a bigger ambition: modeling how data itself could have been produced.
That difference sounds academic until you feel it in practice. Generative modeling often demands stronger assumptions, more careful inference, and more computation, but pays you back with simulation ability, uncertainty reasoning, and flexibility when labels are limited or messy.
Why do probability and statistics sit at the center of generative modeling?
Generative AI is basically probability with ambition. Likelihoods, priors, latent variables, sampling, and approximations to intractable integrals are not side topics here, they are the main dish.
If you like mathematical clarity, you’ll probably enjoy this. If you don’t, you still need it, because a lot of “why did my model fail” questions turn out to be “your probability story is broken.”
How did generative modeling evolve into what we now call “GenAI”?
Historically, generative modeling has roots in classical statistical models and graphical models, then expanded through latent variable modeling and variational methods. Deep learning later made generative models far more expressive, and modern architectures pushed them into text, image, audio, and multimodal generation at scale.
The story isn’t a straight line, though. It’s more like a series of reinventions: old ideas returning with new compute, new parameterizations, and better optimization tricks.
Find the key differences: Agentic AI vs Generative AI vs Traditional AI
Which core model families does STAT 8105 typically cover?
A well-structured STAT 8105 outline usually anchors around three major pillars:
- Probabilistic graphical models, for structured probabilistic reasoning and conditional dependencies.
- Variational inference and latent variable models, for scalable approximate inference when exact Bayesian computation is out of reach.
- Deep generative models, where neural networks become the function approximators for complex distributions.
This is where things get fun. Also frustrating. Sometimes both in the same week.
Why do probabilistic graphical models still matter in 2026?
Graphical models give you a language for conditional independence and structure, not just “throw a network at it.” They’re also a conceptual bridge between classical statistics and modern generative AI.
If you ever wondered why some models generalize better with less data, structure is often the quiet answer.
What makes variational inference such a big deal for latent variable models?
Latent variables let models represent hidden structure, like topics in text or factors in images, but inference becomes hard fast. Variational inference offers a practical compromise: approximate the posterior with a simpler distribution and optimize it.
You get scalability. You also inherit approximation bias. That trade-off becomes a recurring theme.
Learn here: GPT-5.1 vs Claude Opus 4.1: Which AI Model Performs Better?
How do VAEs work, and why do they feel so “statistical”?
What is the encoder decoder framework actually doing?
A VAE uses an encoder to map data into a latent space distribution and a decoder to map latent samples back into data space. Instead of learning a single point embedding, it learns a distribution over embeddings, which is why uncertainty and regularization show up naturally.
It’s not magic. It’s a probabilistic story implemented with neural nets.
What is ELBO, and why does everyone keep talking about it?
The Evidence Lower Bound (ELBO) is the objective that makes training VAEs feasible when the exact marginal likelihood is intractable. It balances reconstruction quality with a regularization term that keeps the latent distribution aligned with a prior.
People obsess over ELBO because it’s the hinge between theory and training. Also because if you misunderstand it, your model “works” but for the wrong reasons.
Where do VAEs shine, and where do they stumble?
VAEs are strong for representation learning, controllable generation, and probabilistic reasoning. Their limitations often appear as blurrier generations (especially in images) and challenges in matching extremely sharp or complex distributions without architectural and objective tweaks.
They’re elegant. They’re not always flashy.
Why do GANs feel powerful, and why can they be a nightmare to train?
What does “generator vs discriminator” really mean in practice?
GANs set up a game: the generator tries to create realistic samples, while the discriminator tries to tell real from fake. Training becomes a minimax optimization problem, which is conceptually simple and practically chaotic.
When it works, the samples can look amazing. When it doesn’t, you’ll stare at collapsed outputs and wonder if the universe is trolling you.
Why are training dynamics unstable for GANs?
GAN instability often comes from the adversarial setup: gradients can vanish, oscillate, or become overly sensitive to architecture and hyperparameters. Mode collapse is the classic failure, where the generator learns to produce limited varieties of outputs that fool the discriminator.
You learn quickly that “it trains” and “it trains well” are two very different statements.
Which GAN variants show up most often in coursework?
Common variants often address stability and quality: Wasserstein-based objectives, conditional GANs, and architectural tweaks that improve gradient behavior. You’ll likely focus less on memorizing names and more on understanding what each modification is trying to fix.
Because in real work, you debug problems, not acronyms.
Why are diffusion models everywhere right now?
What is a denoising diffusion process, conceptually?
Diffusion models learn generation as a gradual denoising procedure: start from noise, then iteratively move toward a sample that looks like data. The training often involves learning how to reverse a noise injection process.
It’s slow-ish compared to some older methods, but the quality and stability can be excellent.
How do diffusion models compare with VAEs and GANs?
VAEs are probabilistic and stable but may sacrifice sharpness. GANs can be sharp but unstable. Diffusion models often trade speed for stability and high-quality generation, making them appealing when sample quality matters and compute budgets allow it.
That’s the pragmatic view. The theoretical view gets deeper, and yes, you’ll probably see it.
Where do diffusion-style ideas show up beyond images?
Diffusion approaches have influenced text, audio, and multimodal generation strategies, though implementations vary widely by modality. In multimodal systems, diffusion or diffusion-like components can help with alignment and high-fidelity synthesis.
In other words, it’s not “an image thing” anymore.
What principles sit under all these models?
Generative AI courses that are worth your time usually return to a few foundational principles:
- Likelihood-based learning: how models assign probability to data and how you optimize it.
- Optimization and sampling: training objectives, gradient behavior, and the reality of approximate sampling.
- Bias, variance, and generalization: how generative models overfit, underfit, and fail in subtle ways.
If you only remember architectures but not these principles, you’ll struggle the moment the model is slightly different from the homework.
What practical applications does STAT 8105 prepare you for?
How does generative AI power text and language generation?
Generative models can produce coherent text, summarize, translate, and adapt tone, and they can be evaluated not just by accuracy but by usefulness, safety, and reliability. You’ll also likely discuss hallucinations, calibration, and uncertainty, because those are not optional topics anymore.
Text generation is where hype meets accountability.
What can image and media synthesis do beyond “cool demos”?
Beyond aesthetics, media generation supports design prototyping, content augmentation, simulation pipelines, and creative tooling. The serious conversations include watermarking, provenance, misuse prevention, and ethical deployment.
The fun part is obvious. The responsibility part is the harder exam.
Why is data augmentation and simulation such a big statistical use case?
When real data is costly, sensitive, or imbalanced, generative models can augment training sets or simulate plausible scenarios. In statistics, this supports stress testing, uncertainty quantification, and robust modeling decisions.
Synthetic data is not automatically “safe” or “correct,” though. It inherits your assumptions, like a kid inherits habits.
What tools and programming skills do you typically use here?
Most implementations lean heavily on Python and sometimes R, depending on the department’s culture and the instructor’s preferences. Common frameworks often include PyTorch or TensorFlow for deep models, plus standard scientific stacks for analysis and visualization.
Computational considerations matter a lot: GPU access, batch sizes, reproducibility, runtime costs, and experiment tracking. This is not a course where “my laptop struggled” is a rare excuse. It’s common.
How are you assessed, and what do you walk away with?
What kinds of assignments and projects are common?
Expect a mix: conceptual problem sets, coding assignments, replication of classic results, and at least one project that forces you to design, train, and evaluate a generative model end to end. Some courses also include reading critiques of research papers, because that’s where you learn to see through hype.
What skills should you have by the end, realistically?
You should be able to explain major generative model families, implement baseline versions, and evaluate them with appropriate metrics and skepticism. You should also understand failure modes and trade-offs, not just best-case demos.
The real skill is judgment. The code is the vehicle.
Why does this matter for research and industry?
Generative modeling skills apply to ML research, statistical methodology, applied data science, and product AI teams building creative or agentic systems. In industry, the edge often comes from knowing when generative AI is the right tool and when it’s an expensive distraction.
Yes, that’s blunt. It’s also true.
Also check the: All ChatGPT AI Models List
Who is STAT 8105 actually for?
What background makes this course feel manageable?
If you’re comfortable with probability, linear algebra, and basic optimization, you’ll be in good shape. Some familiarity with machine learning helps, but strong statistical thinking can compensate for “I haven’t trained a deep net before” nerves.
What prerequisites do you really need, not just on paper?
You’ll want working knowledge of distributions, expectation, conditional probability, and basic inference ideas. You’ll also need enough programming fluency to run experiments, debug models, and interpret results.
Because you will debug. A lot.
What career or academic paths does this align with?
This STAT 8105: Generative Artificial Intelligence Principles and Practices course fits students aiming at AI research, applied ML, statistical research, computational social science, and modern data-driven product work. It also helps if you’re moving toward areas like synthetic data, privacy-aware modeling, or multimodal systems.
What should you take away after reading this outline?
STAT 8105 looks like it’s designed to be the “serious” generative AI course: theory plus practice, probability plus deep learning, and enough realism to prepare you for models that behave badly in the wild.
If you want a single honest line: you’ll learn how generative systems create, how they fail, and how to think like someone who can improve them instead of just using them.
